




UAE
Testvox FZCO
Fifth Floor 9WC Dubai Airport Freezone
 BY
Testvox
BY
Testvox
Testing is the one process every fintech and e-commerce startup knows it needs, yet it quietly becomes the single biggest reason releases stall. You build fast, your team ships features, and then the pipeline grinds. Regressions multiply, QA cycles stretch from days into weeks, and your competitive window narrows. The pressure on CTOs and founders in India and the UAE is real: investors want velocity, customers want reliability, and regulators want compliance. This guide breaks down exactly why testing slows your releases and gives you a tactical, step-by-step path to fix it without trading quality for speed.
| Point | Details |
|---|---|
| Test reductions backfire | Cutting tests appears to speed releases initially but increases costly bugs and rollbacks later. |
| CI pipeline structure matters | Flaky tests and pipeline job dependencies are the top technical culprits behind slow releases. |
| Metrics drive smart fixes | Regularly track DORA and pipeline analytics to pinpoint sticking points before they escalate. |
| Fix processes, not just coverage | Sustainable speedups come from smarter testing design, not brute reduction of test counts. |
Before you can fix slow releases, you need to pinpoint why testing is holding you back.
Most teams assume the solution is to cut tests, skip edge cases, or push straight to automation. That instinct feels logical under deadline pressure. But software testing for startups is not a cost center to trim. It is the mechanism that keeps rollback costs and reputation damage from eating your runway.
The most dangerous pattern is what happens when teams do remove tests. Teams that remove tests often ship faster initially but eventually slow down because defects and rollbacks consume more time than the testing time they removed. That $180K rollback story is not a horror story unique to one company. It is a pattern that repeats across fintech startups that prioritize short-term velocity over structural quality.
Beyond test removal, CI/CD pipeline structure is a major culprit. CI/test suite slowdowns at scale are frequently structural, driven by flakiness causing retries and timeouts, the slowest job creating a floor on total pipeline time, and cascading wall-time when jobs restart. A single flaky test that triggers three retries can add 20 minutes to every pipeline run. Multiply that across dozens of daily commits and you lose hours of deployment time every week.
For fintech and e-commerce teams in the UAE, the problem compounds. Third-party payment gateways, identity verification connectors, and regulatory APIs add external dependencies that are outside your control. When those connectors behave inconsistently in test environments, your suite flags false positives, engineers lose trust in the results, and the entire feedback loop breaks down. Managing distributed testing teams across India and the UAE makes this even harder when environment parity is inconsistent.
Here are the most common symptoms that signal your testing process is structurally broken:
| Symptom | Root cause | Impact on release speed |
|---|---|---|
| Increasing pipeline wall-time | Flaky tests, sequential jobs | Hours lost per week |
| Recurring regressions | Insufficient coverage | Costly rework cycles |
| Unpredictable deployments | Brittle environment setup | Delayed release confidence |
| Engineer distrust of results | High false positive rate | Ignored failures, missed bugs |
| Slow environment provisioning | Manual setup, no automation | Blocked QA queues |
“The slowest job in your pipeline sets the floor for every release. Until you address structural bottlenecks, adding more tests or faster machines will not fix the root problem.”
Now that the common process traps are clear, let’s dig into pinpointing what’s slashing your release speed with proven metrics.

You cannot fix what you cannot measure. The good news is that DORA metrics provide a benchmarkable way to detect where delays and instability come from, but successful teams often extend beyond DORA with additional signals like rework rate and broader measurement so they can explain root causes. DORA stands for DevOps Research and Assessment, and the four core metrics are lead time for changes, deployment frequency, mean time to recover (MTTR), and change failure rate.
Here is a step-by-step diagnostic process you can start this week:
Pro Tip: Use rework rate as your early warning signal. If your rework rate climbs for two consecutive sprints, it almost always means tests were skipped or reduced somewhere upstream. Catch it early and you avoid the compounding cost of fixing bugs that should have been caught before they reached production.
| Metric | Simple tracking | Advanced tracing |
|---|---|---|
| Lead time | Git commit to deploy timestamp | Full pipeline stage breakdown |
| Flakiness rate | Manual test run logs | Automated flaky test detection tools |
| Recovery time | Incident ticket timestamps | Automated alerting with rollback triggers |
| Rework rate | Sprint retrospective notes | Issue tracker tags linked to test failures |
The comparison above shows that even simple tracking gives you enough signal to start making decisions. You do not need a full observability platform on day one. Start simple, then add sophistication as your team grows.
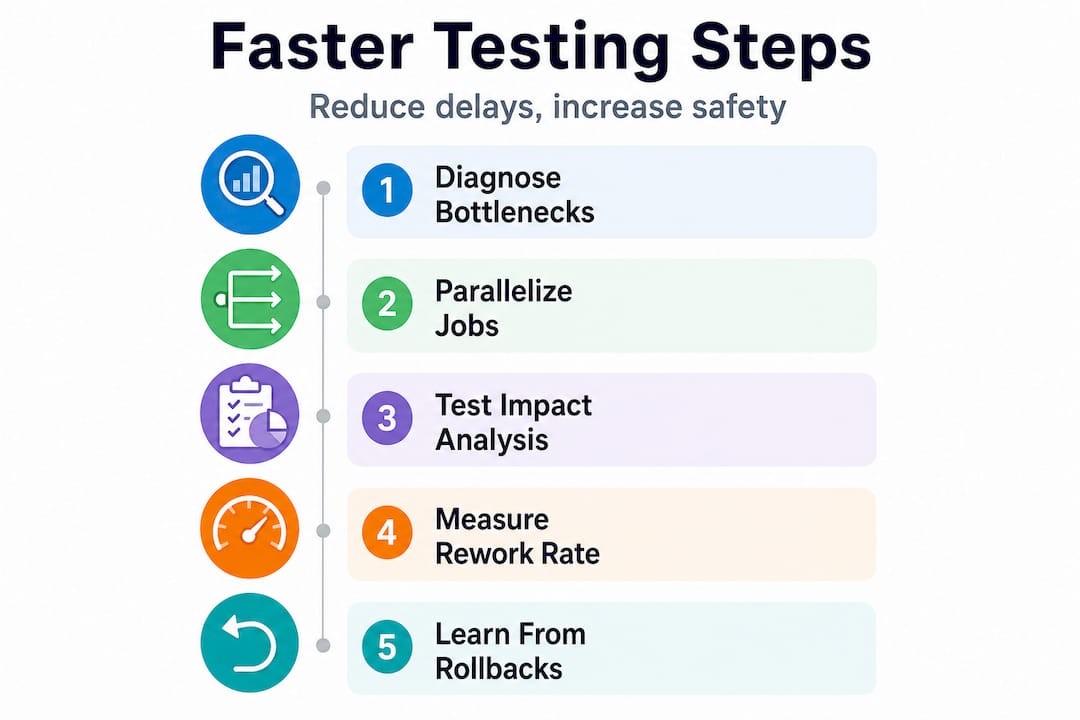
With your bottlenecks in focus, these specific actions will move the needle for both speed and quality.
The goal is not to run fewer tests. It is to run smarter tests faster. Here is how to do it:
Pro Tip: Build a culture where rollbacks are treated as learning tools, not panic events. Every rollback should trigger a structured post-mortem that maps the failure back to a specific gap in your test coverage or pipeline structure. Over time, this creates a feedback loop that systematically eliminates your most expensive failure modes.
Statistic callout: Teams that parallelize CI jobs and implement test impact analysis typically reduce pipeline wall-time by 40 to 60 percent without removing a single test. The speed comes from running the right tests at the right time, not from running fewer tests overall.
Even with smart process changes, common pitfalls can derail velocity. Here is what you cannot afford to skip as you tune your pipeline.
The most damaging mistakes are not obvious. They look like reasonable optimizations until they cause a production incident.
Operational and release friction in fintech can be amplified by dependency maintenance and environment-specific integration work. For example, UAE regulatory and identity connector integration is ongoing, meaning QA and testing timelines can slip if connectors or orchestration are brittle. This is exactly why having a dedicated testing team focused on integration stability pays dividends in regulated markets.
“Automation that runs on brittle infrastructure does not give you speed. It gives you the illusion of speed, right up until a connector breaks in production and you spend three days debugging an environment issue that should have been caught in staging.”
The fix for most of these mistakes is not more tooling. It is discipline. Assign clear ownership for test suite health. Schedule regular pruning sessions. Treat flaky tests as P1 issues, not background noise.
The most common advice floating around engineering communities is to automate more and test less. Cut the slow tests. Skip the edge cases. Move fast. We have seen where that leads, and it is not faster releases. It is a $180K rollback.
Teams that remove tests often ship faster initially but eventually slow down because defects and rollbacks consume more time than the testing time they removed. That story from Medium is not an outlier. It is the predictable outcome of treating testing as optional overhead rather than structural investment.
The elite fintech teams we work with in India and the UAE share one habit: they measure what they skip. They never blindly cut tests. When they remove a test, it is because they have data showing it is redundant or covering deprecated functionality. Every removal is a deliberate, documented decision, not a panic response to a slow pipeline.
Outsourcing your QA or buying an automation platform is not a silver bullet either. We have seen startups spend significant budget on automation frameworks only to find their pipeline is slower than before because the underlying test architecture was never fixed. The tools run faster, but they are running the wrong tests in the wrong order on brittle environments. Speed comes from architecture, not from tooling alone.
The question to ask is not “how do I make my tests faster?” It is “do my tests reflect the actual risk profile of my product?” For a fintech startup processing payments, a 10-second delay in a payment confirmation test is worth tolerating. For a UI color change test, it is not.
Pro Tip: Pull one year of bugs, rollbacks, and test failures and categorize them. You will almost always find that 80 percent of your production incidents trace back to three or four specific areas of your codebase. Optimize coverage there first. That analysis will tell you what to fix, not what to cut. Pair this with an honest look at outsourcing versus in-house testing to decide where specialist support adds the most leverage.
If you have read this far, you already know that faster releases come from smarter testing architecture, not from cutting corners. The challenge is that building that architecture takes time, expertise, and focus that most startup teams simply do not have while shipping product.
Testvox works with fintech and e-commerce startups in India and the UAE to diagnose exactly what is slowing their releases and fix it. From accessibility testing solutions that ensure compliance without adding pipeline weight, to a proven QA auditing process for Y Combinator-backed startups that delivers results fast, the team brings deep domain expertise to every engagement. The quick auditing service for startups is specifically designed for teams nearing a beta or major release who need a comprehensive, rapid quality check without a months-long engagement. If your pipeline is slow and your releases feel unpredictable, this is where to start.
DORA metrics measure software delivery speed and stability across four dimensions, making it straightforward to detect exactly where your testing or deployment process is introducing delays. They give you a shared, benchmarkable language for diagnosing and improving release performance.
Look at failed pipeline jobs, flaky test rates, and retry counts first. CI/test suite slowdowns are frequently structural, driven by flakiness, the slowest job setting a pipeline time floor, and cascading restarts, so isolating these signals will confirm whether testing or infrastructure is your primary bottleneck.
Removing tests might produce a short-term speed gain but almost always leads to production bugs and rollbacks that cost far more time than the tests saved. Teams that remove tests consistently find that defect and rollback costs exceed the time they originally saved.
Flaky tests cause random failures that trigger retries or full pipeline restarts, which extends total runtime unpredictably. Slow pipelines are a structural issue where the slowest job sets a hard floor on how fast any build can complete, regardless of how fast the other jobs run.

Let us know what you’re looking for, and we’ll connect you with a Testvox expert who can offer more information about our solutions and answer any questions you might have?