
 27 June 2025
27 June 2025







UAE
Testvox FZCO
Fifth Floor 9WC Dubai Airport Freezone
 15 June 2026
15 June 2026
 10 Minutes Read
10 Minutes Read  BY
Harshit Gupta
BY
Harshit Gupta
A founder I spoke to in April was somewhere between proud and rattled. Over a single weekend, his two engineers had used Playwright’s built-in test agents to spin up close to 300 end-to-end tests. Coverage numbers jumped. The CI dashboard went a very satisfying shade of green. Three weeks later a broken checkout flow shipped anyway — straight past all 300 passing checks — and a paying customer found it before anyone on the team did.
Playwright crossed roughly 33 million weekly downloads this year and shipped v1.60 in May. Since v1.56 it ships with agents that can plan, write, and even repair tests largely on their own — you run npx playwright init-agents, point it at an assistant like GitHub Copilot or Claude Code, and it works off the page’s accessibility tree instead of the raw HTML. Writing a test, the slow and finicky part of the job for most of the last decade, is close to free now. Describe a flow in plain English and you’ll get working TypeScript back in a couple of minutes.
You’d think that reduces the need for a specialist. In practice it does the opposite.
When anyone can generate a hundred tests before lunch, the scarce skill stops being typing them out. It becomes knowing which hundred to keep, which to bin, why a green checkmark is quietly lying to you, and how to build the thing so it survives the next redesign. That’s judgment. And judgment is exactly where a Playwright expert earns their fee.
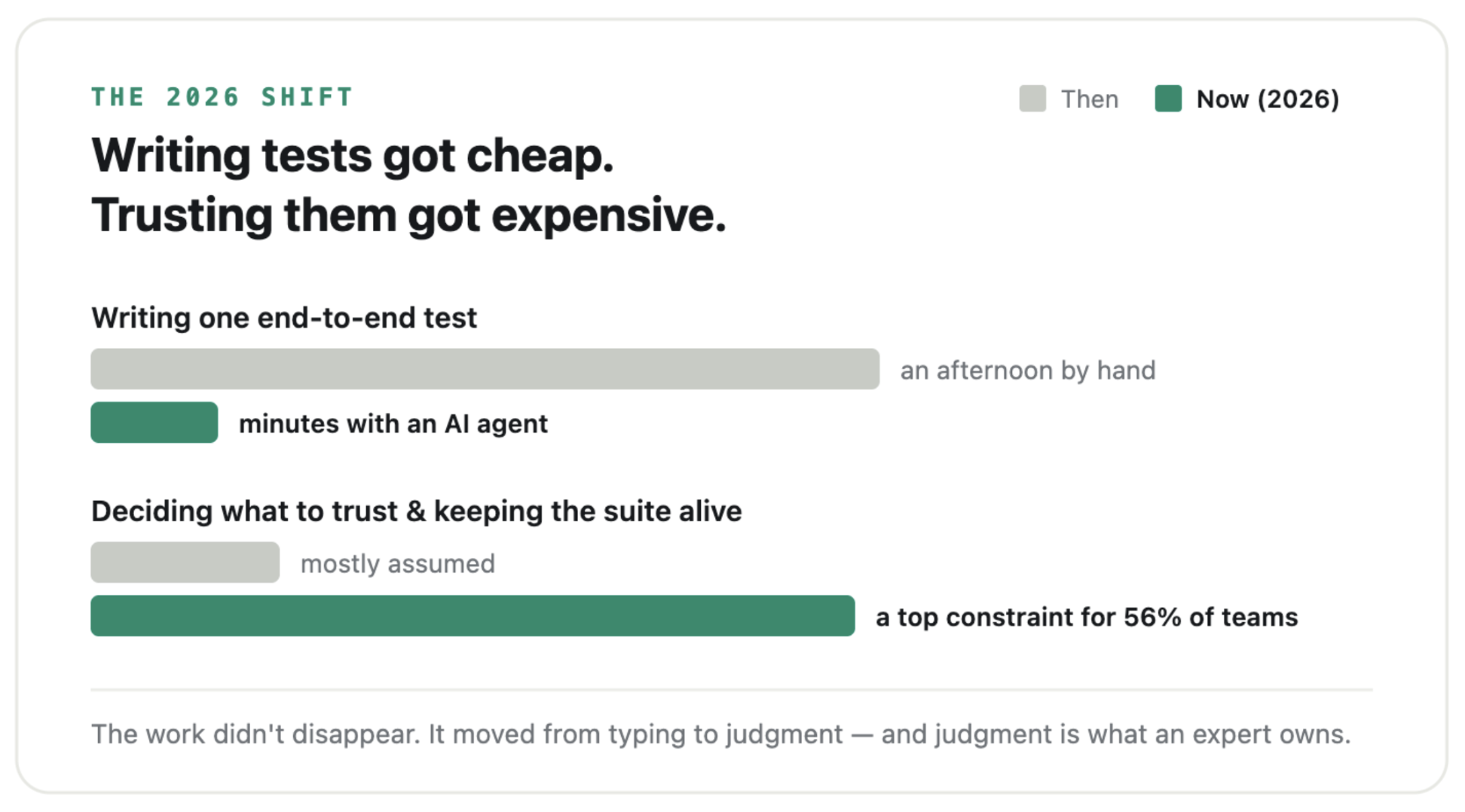
The work didn’t go away in 2026. It moved — from writing tests to deciding which ones to believe.
So how do you tell a team that’s genuinely fine from one that’s quietly piling up a problem? Here are the five signs I’d watch for. You’ll notice none of them is “your tests are flaky.” That was the 2019 answer. These are the ones that actually bite now.
This is the one that should keep you up at night, because everything looks healthy. The pipeline passes. The dashboard is green. And users keep finding things your suite swore weren’t there.
Usually it means the tests are asserting the wrong things — clicking through happy paths an agent found easy to reach, while the messy real-world flows (expired sessions, half-filled forms, a slow payment provider) go unchecked. A test that always passes isn’t proving your app works. It’s proving the test is easy.
The clearest tell is cultural: when a test goes red, what’s the first thing your team does? If the honest answer is “re-run it and see if it passes,” people have already stopped believing red means broken. At that point the suite is decoration. Getting green to mean something again — coverage mapped to actual business risk rather than to whatever was convenient to automate — is the first thing a good Playwright engineer fixes.
This is the new one, and it’s sneaky because it arrives disguised as progress.
The agents are genuinely good. A flow that used to take an afternoon to script by hand comes back as working TypeScript in minutes. Wonderful. Right up until you’re staring at 600 spec files, a third of them testing the same path three slightly different ways — and you’ve quietly joined the 60% of automation owners who admit the whole effort ended up costing more than they forecast.
Generated tests are a first draft, not a deliverable. Somebody still has to prune the duplicates, set naming and structure conventions, and decide what’s actually worth keeping alive. If your test count is climbing faster than your team’s understanding of what those tests do, you don’t have great coverage — you have a maintenance bill with a delay on it.
Move a button, rename a CSS class, restyle a form, and suddenly eleven unrelated tests fall over. That’s not bad luck. It means your tests are bolted to the markup instead of to behaviour.
The fix is well understood and slightly boring, which is precisely why teams in a hurry skip it: role-based locators like getByRole(‘button’, { name: ‘Checkout’ }), stable test IDs, and a page-object layer so a change lives in one place instead of forty. Playwright’s agents lean this way by default — they navigate by “Role: button, Name: Checkout” rather than div.btn-v3 — but only if someone sets and enforces the convention. Left to drift, a suite slides back to brittle selectors within a month. Keeping it from drifting is architecture work, and architecture work needs an architect.
If your suite takes longer to run than your app takes to build, it becomes the bottleneck — and the moment something is a bottleneck under deadline pressure, people start quietly skipping it. “We’ll run the full suite tonight.” You know how that ends.
Speed here is mostly an engineering problem with known answers: sharding, parallel workers, tagging smoke runs separately from full regression, and retry policies that don’t paper over real failures. Worth knowing: in one 2026 industry roundup, 56% of teams named test maintenance a major constraint, and 45% needed three or more days to update their tests after a system change. That time doesn’t vanish just because nobody owns it. It comes out of your feature roadmap instead.
Every team has them: the one engineer who actually gets the framework. They know why the auth setup is the way it is. They can read a trace in their sleep. And when they take two weeks off, releases get nervous.
This is the most expensive sign on the list because it’s invisible right up until that person updates their LinkedIn. The conventions are in their head, the framework is undocumented, and nobody else can debug a failing run with confidence. A real fix isn’t hiring a clone — it’s institutionalising the knowledge: written conventions, a documented framework, and at least two people who can keep the lights on. That’s something an experienced engineer or an outside team builds on purpose; it rarely happens by accident.
Be honest about how many of those five describe your team. One or two on a young product is usually fine; just keep half an eye on the maintenance load. Three or more, and you’re paying a tax you can’t see on the balance sheet yet.
Here’s a simple way to settle it:
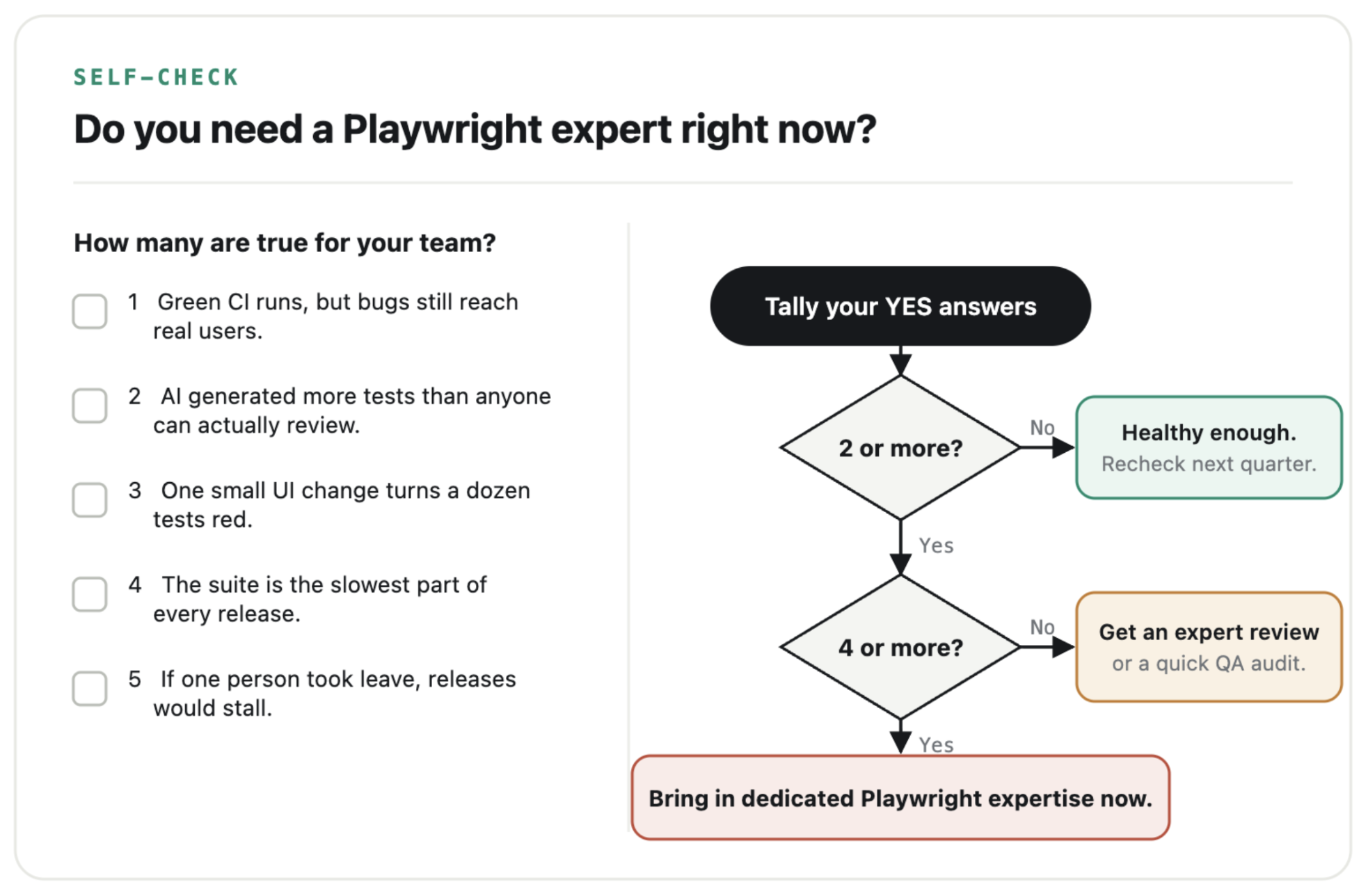
Count your yeses, then follow the arrows. The honest number is usually one higher than the one you say out loud.
The role has changed, and it’s worth being clear about how, because the old picture leads people to the wrong decision.
You are not hiring someone to out-type an AI. The AI wins that race, and it’s not close. What you’re hiring is closer to a test architect: someone who sets the locator and test-data conventions, designs the CI pipeline, reviews what the agents churn out, and decides what the suite is actually responsible for proving. The typing is automated. The accountability isn’t.
And it does need a human holding it, because the agents aren’t as autonomous as the demos suggest. When researchers put frontier web agents on realistic live-website tasks instead of cherry-picked benchmarks, the results came in well below what earlier reports had claimed — and even now, 74% of practitioners say AI-driven testing still needs a human validating the output. They’re brilliant fast drafters and unreliable owners. Someone experienced has to stand between the draft and production.
That expertise comes in a few shapes, and they’re not equally priced. A senior in-house hire if you can find and afford one. An embedded engineer through staff augmentation if you want the skill without the headcount commitment. Or an outside team that runs a one-off architecture review or QA audit and leaves your own engineers with conventions they can carry forward. For most early-stage teams, the audit-first route is the cheapest way to find out whether you’ve got a quick fix or a rebuild on your hands.
If two or more of those signs landed a little too close to home, that’s the natural moment to bring in a second set of eyes. Testvox works with startup and SME teams — mostly across India and the UAE — to review Playwright setups, embed automation engineers, and get suites back to a state the team genuinely trusts. You can browse the automation case studies to see what that looks like in practice, or just book a short assessment. Even an hour of review usually tells you which of the five signs you’re really dealing with.
Can’t AI just replace a Playwright expert now?
It replaces the slowest part of their job — writing the first draft of a test — and it’s great at it. It doesn’t replace deciding what to test, judging whether coverage maps to real risk, or owning a suite people can trust. Those are the parts that were always the hard parts; AI just made them more visible.
At what stage do we actually need this — MVP, or later?
Earlier than most founders expect, but lighter than they fear. You don’t need a full-time automation hire at MVP. You do need someone to set sane conventions before you’ve generated 500 tests on top of bad ones, because unpicking that later costs far more than getting it right at 50.
Should we hire in-house or outsource it?
Depends on how central testing is to your product and how stable your headcount is. If quality is a core, permanent need, build the muscle internally. If you need the skill now and can’t justify a permanent seat, an embedded engineer or a fixed-scope audit gets you there faster and cheaper.
How do I tell a real Playwright expert from someone who’s just used it?
Ask them to walk you through a real suite they’ve built — not a slide. Listen for how they handle authentication state, test data across parallel runs, and flaky failures. People who think in systems answer very differently from people who think in scripts.


AI Test Architect & Lead SDET with 11+ years of expertise in Playwright, API testing, automation, and AI/LLM evaluation. He focuses on delivering high-quality, user-centric software through AI-assisted testing, efficient testing strategies, and continuous innovation. Connect with him on



Let us know what you’re looking for, and we’ll connect you with a Testvox expert who can offer more information about our solutions and answer any questions you might have?