
 1 April 2024
1 April 2024







UAE
Testvox FZCO
Fifth Floor 9WC Dubai Airport Freezone
 6 August 2025
6 August 2025
 5:55 MIN Read time
5:55 MIN Read time  BY
Vignesh Thangaraj
BY
Vignesh Thangaraj
Testvox review focused on a JavaScript/TypeScript-based automation framework built using the Playwright testing tool. The client had already developed a functional automation suite, and our objective was to assess the overall architecture, identify opportunities for optimization, and provide technical recommendations for scaling the framework more effectively. The scope of our audit spanned several key areas, including code quality and maintainability, with an emphasis on ensuring that the framework followed clean coding principles and design patterns that would support long-term sustainability. We also examined the structure and implementation of the Page Object Model (POM), aiming to identify improvements that could enhance modularity and readability.
Another critical area of focus was the reusability of test fixtures. We evaluated whether the framework leveraged shared configurations and initialization routines efficiently across multiple test cases. Logging and error-handling mechanisms were reviewed to determine whether test failures were being captured meaningfully and whether the logging structure supported quick debugging and traceability. Our audit also included a review of the CI/CD integration, particularly the configuration of GitHub Actions, to verify whether the pipeline supported flexible, environment-based test execution.
Additionally, we assessed how the framework handled integration with third-party reporting tools like TestRail. This included evaluating the strategy used to submit test results and identifying potential risks such as API rate limits or excessive request overhead. Finally, we looked at how test data was managed within the framework and whether the structure supported scalability across multiple environments. The audit was conducted through manual code review and static analysis methods by Testvox Senior Test Automation Consultant, Vignesh Thangaraj, ensuring a detailed and objective evaluation of both the technical and architectural aspects of the framework.
|
Area |
Finding |
Recommended Improvement |
Priority |
| Page Object Model | Complex folder structure with redundant classes | Consolidate POM into modular, intuitive folders for readability | High |
| Test Fixtures | Page objects initialized within each test | Use fixtures to instantiate shared objects across all tests | High |
| Data Handling | Repeated login logic and account creation | Use Playwright’s StorageState to reuse auth states | High |
| Logging & Assertions | Extensive try-catch usage | Simplify using promise .catch() and custom messages with expect | High |
| CI/CD Config | No environment-based test execution | Enhance GitHub Actions to support dropdown env config | Medium |
| Environment Settings | Manual toggling across environments | Introduce separate env files for smooth cross-env testing | Medium |
| TestRail Integration | Risk of 429 errors due to single test updates | Switch to batch result submission for API efficiency | Medium |
| Test Data | Hardcoded random values | Use Faker library for better data control and test clarity | Low |
| Commit Hygiene | No lint/stage hooks | Introduce Husky with ESLint, Prettier, and Playwright plugins | Low |
|
Category |
Observation |
Status |
| DRY Principle [POM ] | Complicated can be simplified | ❌ Needs Fix |
| Modularity | Functions are often not reusable | ⚠️ Partial |
| Naming Conventions | Inconsistent usage | ⚠️ Improve |
| Documentation | Missing/incomplete docstrings | ❌ Missing |
| Environment toggle | Requires manual intervention | ❌ Needs Work |
One of the most significant opportunities for improvement was the existing Page Object Model (POM) structure. The current implementation splits components between page-objects/ and pages/ directories, which introduces unnecessary complexity and redundancy. We recommended consolidating both into a single, unified structure to improve clarity and accessibility.
Additionally, the locator class defined each locator as a function—sometimes parameterised—and was used directly in page classes. Since the interface layer added no tangible benefit and lacked strict typing enforcement, it could safely be deprecated in favour of direct class-based access.
To enhance encapsulation, any internal-use-only functions should be marked as private. This ensures that spec files access only intended methods while maintaining clean boundaries between layers.
As some classes began to exceed manageable sizes, we suggested a modular design approach. For example, grouping dashboard-related components into a dashboard/ directory keeps responsibilities focused and makes the codebase easier to navigate and maintain. This structure enables new team members to quickly understand the test architecture without excessive ramp-up time.
// Code
❌ Before:
|– pages/
|– page-objects/
|– dashboard.page.ts
✅ After:
|– page-objects/
|– dashboard/
|– index.ts
|– widgets.page.ts
By simplifying the POM structure and eliminating unnecessary abstractions, the framework becomes more scalable, maintainable, and developer-friendly—without sacrificing flexibility or power.
“When test automation scales, architecture becomes just as critical as test coverage. A clean Page Object Model makes the difference between speed and struggle.”
– Vignesh Thangaraj, Senior Test Automation Consultant at Testvox
To follow the DRY (Don’t Repeat Yourself) principle, we recommended moving commonly used assertions out of test spec files and into a centralized location within the Page Object Model (POM).
Rather than duplicating assertion logic across multiple test cases, all validation logic can be stored in a structured JSON-based assertion file, or defined as reusable methods inside page objects. These assertions can then be invoked via shared utility methods from the spec files, making validations standardized, readable, and easily maintainable.

The spec file will invoke predefined assertions through the centralized assert method, ensuring standardized validation across test cases.
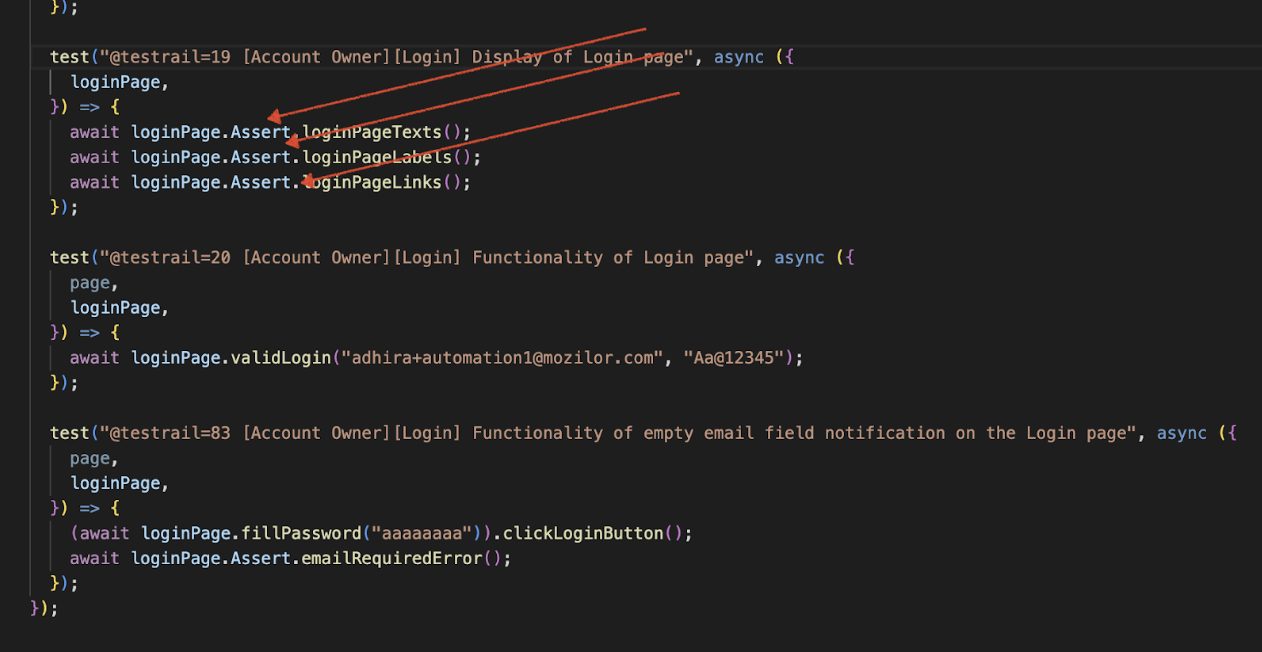
We are chaining functions together to enhance readability and maintain a clear flow of execution. This not only makes the test cases easier to understand for developers, but also improves clarity for Business Analysts (BA) and Product Owners (PO), making the tests more transparent and accessible to a wider audience.
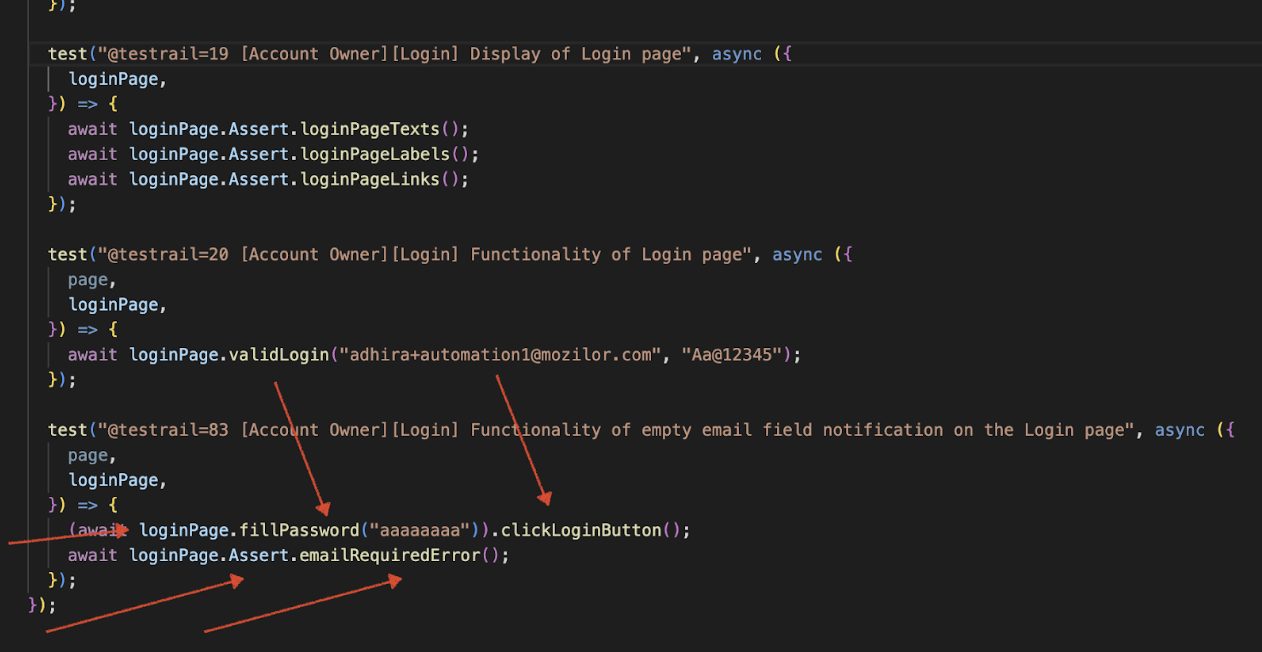
To follow the DRY (Don’t Repeat Yourself) principle, we can create and initialize shared objects within the test fixture. These objects can then be accessed across all test cases within the same test suite. This approach helps avoid repetitive instantiation in each test, promotes reusability, and ensures a cleaner and more maintainable test structure.
Authentication state (including cookies and local storage) is stored on the filesystem and reused across tests to avoid repeated login steps. The most common setup is authenticating once in a setup project and sharing the authenticated state with all tests for efficiency. For tests that modify server-side data or run in parallel, assign unique accounts per worker to isolate their state and avoid interference. Avoid repeatedly authenticating in each test for faster execution, and ensure expired state files are cleaned up as needed
Playwright Documentation: https://playwright.dev/docs/auth#core-concepts
I’ve noticed that try-catch blocks are used throughout the codebase. For improved readability and cleaner syntax, we can utilize only catch blocks with Promises, rather than wrapping every operation in try-catch.
Additionally, for assertions using expect blocks, we can pass custom error messages directly as arguments, eliminating the need to handle errors within try-catch statements. every expect can have a message will help us in debugging.
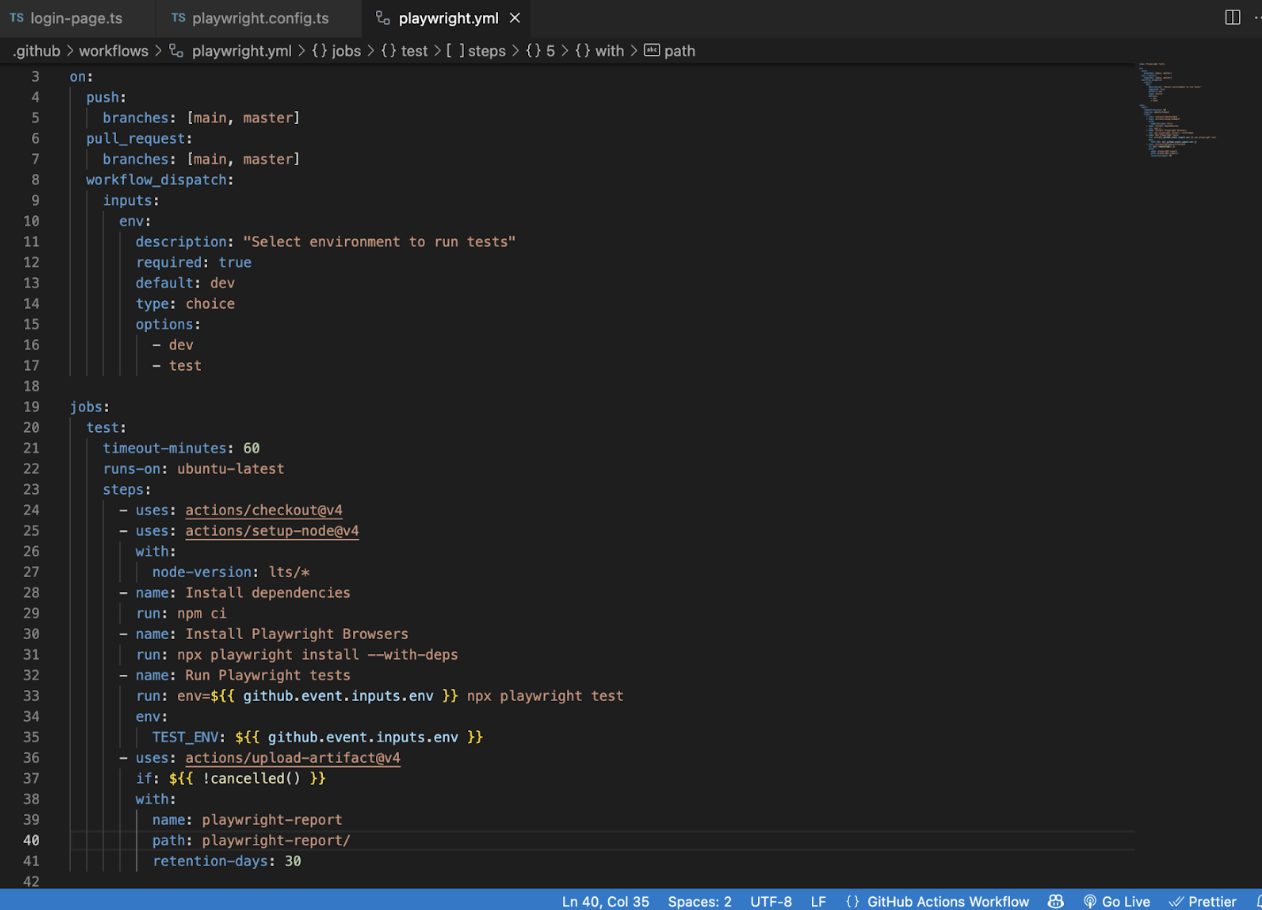
Load each test execution using an environment flag to run tests against the designated environment. This approach encourages consideration for cross-environment compatibility and ensures code is ready for different deployment contexts. Utilizing environment-specific execution is a common and essential feature in most modern test frameworks.
Passing an environment (env) argument to your CI pipeline is a widely adopted framework design across modern development teams. This practice enables consistent, flexible deployments and test execution across various environments (e.g., development, staging, test, production).
Some tests currently contain hardcoded input values, often using random strings or numbers to validate user interface behavior or trigger failure conditions. Instead of hardcoding these values, we can use the Faker library to generate realistic and randomized test data.
Using Faker not only makes the test code more readable and expressive, but also clearly indicates the intention of using dynamic data as function arguments. It also provides a wide range of utilities to generate various types of random information, making it useful in other parts of the test suite as well. It’s a valuable tool worth exploring for maintaining robust and flexible test automation.
Documentation: https://fakerjs.dev/guide/


Utilise Husky to configure Git hooks and lint-staged to execute checks specifically on staged files. Set up ESLint, Prettier, and TypeScript validations to run automatically on every commit. Additionally, enforce Playwright test best practices by integrating eslint-plugin-playwright for Playwright-specific linting.
Husky Documentation: https://typicode.github.io/husky/get-started.html
Playwright Doc: https://www.npmjs.com/package/eslint-plugin-playwright
|
Benefit |
Description |
| Early error detection | Blocks bad code before commit |
| Consistency | Enforces formatting and style guides |
| Clarity | Developers get immediate feedback |
| Team alignment | Keeps codebase consistent across all devs |
When integrating automated test results with TestRail, it’s common to push results during or immediately after each test. However, updating the TestRail API for every single test case individually has several drawbacks:
|
Problem |
Impact |
| API Rate Limits (e.g., 429 Too Many Requests) | Risk of hitting rate limits imposed by TestRail |
| Slower Build Times | Continuous API calls add up, increasing test suite runtime |
| Unnecessary Network Overhead | Every request initiates a connection and adds latency |
| Visibility Delays | Unbatched results may show up inconsistently in the UI |
Instead of updating TestRail after each test, you accumulate results in memory during test execution. Once all tests (or a Suite/Group) finish, results are submitted in one API call or in optimized chunks.
19 June 2024

Vignesh Thangaraj is a seasoned Test Automation Consultant with over 12 years of experience in the software testing industry. Vignesh specializes in both mobile and web application automation, with hands-on expertise in tools and technologies such as Java, Playwright, Selenium, Appium, TestNG, and Cypress.



Let us know what you’re looking for, and we’ll connect you with a Testvox expert who can offer more information about our solutions and answer any questions you might have?